MSSQL, PRIMARY KEY CLUSTERED 의미
- Database
- 2023. 4. 4.
마이크로소프트 SQL Server에서 테이블을 생성할 때 컬럼에 PRIMARY KEY CLUSTERED를 부여하는 것은 PRIMARY KEY와 CLUSTERED INDEX 두 가지 개념을 적용하는 것입니다.
PRIMARY KEY CLUSTERED
1. PRIMARY KEY : 데이터베이스 테이블에서 고유한 식별자 역할을 하는 열 또는 열의 조합을 나타냅니다. PRIMARY KEY로 지정된 컬럼은 값이 NULL이어서는 안 되며 각 행에 대해 고유한 값을 가져야 합니다.
2. CLUSTERED INDEX : 테이블의 물리적인 정렬 방식을 결정하는 인덱스입니다. 클러스터 인덱스는 테이블 데이터가 디스크에 저장되는 방식을 정의하며, 인덱스에 따라 행이 정렬됩니다. 이로 인해 데이터 검색을 빠르게 수행할 수 있습니다.
결론적으로 PRIMARY KEY CLUSTERED를 적용한 컬럼은 기본키이면서 인덱스에 따라 행이 정렬됩니다. 사실 PRIMARY KEY를 지정하면 기본적으로 CLUSTERED 속성으로 생성되기 때문에 CLUSTERED를 붙이지 않아도 되지만 명시적으로 지정해서 사용하곤 합니다.
예시 1)
학생들의 정보를 저장하는 테이블이 있다고 가정해 보겠습니다. 각 학생은 고유한 학번(StudentID)를 가지고 있습니다. 여기서 학번(StudentID)를 PRIMARY KEY로 설정해 학번을 기준으로 학생들을 구분할 수 있습니다. 여기에 CLUSTERED 속성을 적용하면, 학번(StudentID)을 기준으로 데이터가 정렬되어 저장됩니다.
PRIMARY KEY CLUSTERED를 적용한 'Students' 테이블을 생성하는 구문은 아래와 같이 쓸 수 있습니다.
CREATE TABLE Students (
StudentID INT NOT NULL,
FirstName NVARCHAR(50) NOT NULL,
LastName NVARCHAR(50) NOT NULL,
Age INT,
CONSTRAINT PK_StudentID PRIMARY KEY CLUSTERED (StudentID)
);
예시 2)
직원 테이블에서 EmployeeID 컬럼을 PRIMARY KEY로 설정하며 CLUSTERED 속성을 적용할 수 있습니다.
CREATE TABLE Employees (
EmployeeID INT NOT NULL,
FirstName NVARCHAR(50) NOT NULL,
LastName NVARCHAR(50) NOT NULL,
Department NVARCHAR(50),
HireDate DATE,
CONSTRAINT PK_EmployeeID PRIMARY KEY CLUSTERED (EmployeeID)
);
예시 3) 두 개 이상의 복합 기본키 설정
PRIMARY KEY를 두 개 이상 조합해서 지정할 수도 있습니다.
예를 들어, 도서관에서 책을 관리하는 테이블이 있습니다. 이 테이블에서 Shelf와 Position 두 열을 조합해서 고유한 위치를 나타내는 복합 기본 키를 생성합니다.
CREATE TABLE LibraryBooks (
BookID INT NOT NULL,
Title NVARCHAR(100) NOT NULL,
Author NVARCHAR(100) NOT NULL,
Shelf INT NOT NULL,
Position INT NOT NULL,
CONSTRAINT PK_Shelf_Position PRIMARY KEY CLUSTERED (Shelf, Position)
);LibraryBooks 테이블에서 책 위치를 고유하게 식별하기 위해 Shelf와 Position 두 열에 PRIMARY KEY를 지정했습니다.
이 테이블에 아래와 같은 데이터가 LibraryBooks 테이블에 저장되어 있습니다.
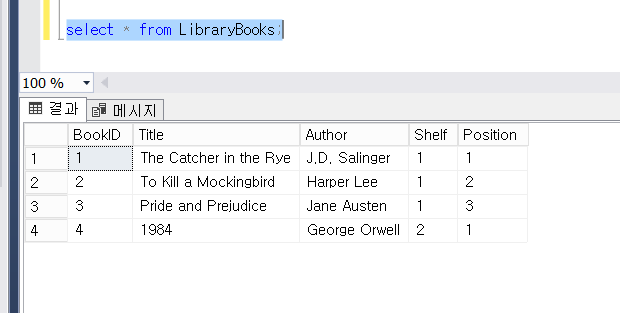
먼저 짚고 넘어갈 것은 "고유해야하는" 기본키가 어떻게 2개 일 수 있지?라는 의문입니다. 테이블당 기본키는 하나인 게 맞지만, 기본키는 컬럼을 조합해서도 만들 수가 있다는 점을 알아야 합니다. 다시 말해, 복합 기본키의 경우, 각 열의 값이 개별적으로 고유할 필요는 없고, 열의 조합이 고유하면 괜찮습니다.
다시 돌아와서, 만약 책장 1에 있는 모든 책 정보를 찾기 위해서는 아래와 조회할 것입니다.
SELECT * FROM LibraryBooks WHERE Shelf = 1;
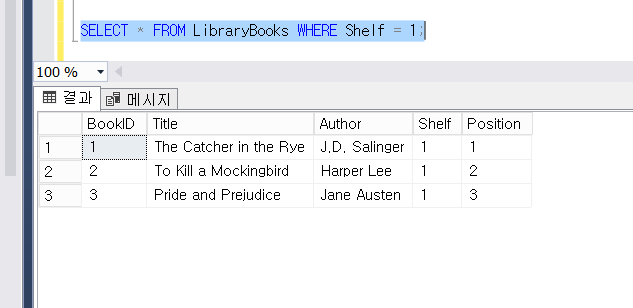
또 의문이 들 수 있습니다. 이게 기본키 설정과 무슨 상관일까요? 기본키 지정 없이도 Shelf 값을 조건으로 조회하는 건 가능한데 말입니다. 맞습니다. 하지만 위에서 언급했듯 기본키와 함께 CLUSTERED 속성을 적용하면 기본키를 기준으로 데이터를 정렬 및 저장합니다. 이는 검색 성능을 높여주는 효과가 있습니다.
CLUSTERED 사용하는 이유
데이터의 물리적인 순서를 결정하는 이유는 디스크 공간을 효율적으로 사용하고 데이터 검색 성능을 최적화하기 위해서입니다. 데이터베이스는 디스크에 데이터를 저장하고 검색하는 시스템이므로, 저장된 데이터의 물리적인 순서는 데이터베이스 성능에 큰 영향을 미칩니다.
CLUSTERED 인덱스를 사용하면 데이터가 인덱스를 기준으로 정렬되어 저장되므로, 검색 작업이 빠르게 수행됩니다. 이유는 다음과 같습니다.
1. CLUSTERED 인덱스는 트리 구조를 가지며, 인덱스 키를 기준으로 데이터가 정렬됩니다. 이로 인해 관련 데이터가 인접한 디스크 블록에 저장되기 때문에, 데이터를 찾기 위한 디스크 접근 횟수가 줄어들고 검색 성능이 향상됩니다.
2. 인덱스 키를 기준으로 정렬된 데이터를 가지므로, 특정 범위의 데이터를 검색할 때 빠른 성능을 제공합니다. 예를 들어, 특정 날짜 범위의 데이터를 검색하는 경우, 데이터가 정렬되어 있기 때문에 연속된 디스크 블록에서 데이터를 읽을 수 있어 성능이 향상됩니다.
그러나 CLUSTERED 인덱스의 단점도 존재합니다. 데이터 삽입, 수정, 삭제 작업의 성능이 느려질 수 있습니다. 이는 새로운 데이터를 삽입하거나 기존 데이터를 수정, 삭제할 때 인덱스 키를 기준으로 데이터를 정렬해야 하기 때문입니다.
'Database' 카테고리의 다른 글
| 오라클, 소유자가 아닌 테이블 조회 (스키마) (0) | 2023.04.06 |
|---|---|
| 오라클, dual 테이블이란? (0) | 2023.04.05 |
| MSSQL, GETDATE() 함수 사용법 (0) | 2023.04.04 |
| SQL, CASE WHEN THEN 구문 사용법 (0) | 2023.04.04 |
| MS SQL Server MDF, LDF 저장 위치 / 변경 방법 (0) | 2023.03.27 |